# JS
# 内置类型
JS 分为八种内置类型,八种内置类型又分为两大类型:基本类型和引用类型(Object)。
基本类型有七种: number,bigint,string,boolean,symbol,undefined,null。
其中,JS 的数字类型是浮点型的,没有整形。并且,浮点类型基于 IEEE 754 标准实现,在使用过程中会遇到某些 Bug。NaN 也属于 number 类型,但 NaN 不等于自身。
对于基本类型,若使用字面量定义方式,则这个变量只是一个字面量,只有在必要的时候才转换为对应的数据类型。
let a = 111; // 这只是字面量,不是 number 类型
a.toString(); // 使用时候转换为相应对象类型
对象(Object)是引用类型,在使用过程中会遇到浅拷贝和深拷贝的问题。
let a = { name: 'FE' };
let b = a;
b.name = 'EF';
console.log(a.name); // EF
# Typeof
typeof 对于基本类型,除了 null 外,都可以显示正确的类型。
typeof 1; // 'number'
typeof 1n // 'bigint'
typeof '1'; // 'string'
typeof true; // 'boolean'
typeof Symbol(); // 'symbol'
typeof undefined; // 'undefined'
typeof b; // 'undefined'(b 没有声明)
typeof 对于对象,除了函数都会显示 object
typeof {} // 'object'
typeof [] // 'object'
typeof console.log // 'function'
对于 null 来说,虽然它是基本类型,但是会显示 object,这是一个存在很久的 Bug
typeof null // 'object'
PS:为什么会出现这种情况?因为 JS 的最初版本中,使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息。000 开头代表是对象,然而 null 表示全零,所以将它错误判断为 object。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
如果想获取一个变量的正确类型,可以通过 Object.prototype.toString.call(x)。这样我们就可以获取类似 [object Type] 的字符串。
let a;
// 我们也可以这样判断 undefined
a === undefined
// 但是 undefined 不是保留字,能够在低版本浏览器被复制
let undefined = 1;
// 这样判断就会出错
// 所以可以用下面的方式来判断,并且代码量更少
// 因为 void 后面随便跟上一个组成表达式
// 返回就是 undefined
a === void 0
# 类型转换
# 转 Number
| 原始类型值 | 结果 |
|---|---|
| Number | number |
| Bigint | number |
| String | number 或 NaN |
| Boolean | 0 或 1 |
| Symbol | TypeError |
| Undifined | NaN |
| Null | 0 |
| 引用类型值 | 结果 |
| Object | NaN |
| Array | number(一个数值元素或空) 或 NaN |
| Function | NaN |
转换规则
const obj = { x: 1 };
Number(obj);
// 等同于
if (tyepof obj.valueOf() === 'object') {
Number(obj.toString());
} else {
Number(obj.valueOf());
}
# 转 String
| 原始类型值 | 结果 |
|---|---|
| Number | "number" |
| Bigint | "number" |
| String | string |
| Boolean | "true" 或 "false" |
| Symbol | "symbol" |
| Undefined | "undefined" |
| Null | "null" |
| 引用类型值 | 结果 |
| Object | "[object Object]" |
| Array | string,如 String([1, 2, 3]) —> "1, 2, 3" |
| Function | string |
# 转 Boolean
| 值 | 结果 |
|---|---|
| 0(包含 +0 和 -0) | false |
| 0n(包含 -0n) | false |
| NaN | false |
| ''(空字符串) | false |
| false | false |
| undefined | false |
| null | false |
| 其他 | true |
# 对象转基本类型
对象转基本类型时,先调用 valueOf,然后调用 toString。并且,这两个方法是可以重写的。
let a = {
valueOf() {
return 0;
}
}
当然,你也可以重写 Symbol.toPrimitive,该方法在对象转基本类型时,调用优先级最高。
let a = {
valueOf() {
return 0;
},
toString() {
return '1';
},
[Symbo.toPrimitive]() {
return 2;
}
}
1 + a // => 3
'1' + a // => '12'
# 四则运算符
只有加法运算时,其中一方为 String 类型,会把另一方转为 String 类型。而在其他运算中,只要其中一方为 Number 类型,则另一方转为 Number类型。并且,加法运算会触发三种类型转换:转换为原始值、转换为数字、转换为字符串。
1 + '1' // '11'
2 * '2' // 4
[1, 2] + [2, 1] // '1,22,1'
// [1, 2].toString() -> '1, 2'
// [2, 1].toString() -> '2, 1'
// '1, 2' + '2, 1' = '1, 22, 1'
对于加号需要注意这个表达式 'a' + + 'b'
'a' + + 'b' // 'aNaN'
// 因为 + 'b' -> NaN
// 你也许在一些代码中看到过 + '1' -> 1
# == 操作符
1. 若 Type(x) 与 Type(y) 相同,则
a. 若 Type(x) 为 Undefined,返回 true。
b. 若 Type(x) 为 Null,返回 true。
c. 若 Type(x) 为 Number,则
i. 若 x 为 NaN,返回 false。
ii. 若 y 为 NaN,返回 false。
iii. 若 x 与 y 为相同数值,返回 true。
iv. 若 x 为 +0 且 y 为 -0,返回 true。
v. 若 x 为 -0 且 y 为 +0,返回 true。
vi. 其他,返回 false。
d. 若 Type(x) 为 String,则当 x 和 y 为完全相同的字符序列(长度相等且相同字符在相同的位置)时,返回 true。否则,返回 false。
e. 若 Type(x) 为 Boolean,当 x 和 y 同为 true 或 false 时,返回 true。否则,返回 false。
f. 若 Type(x) 为 Object,当 x 和 y 引用同一对象时,返回 true。否则,返回 false。
2. 若 x 为 null 且 y 为 undefined,返回 true。
3. 若 x 为 undefined 且 y 为 null,返回 true。
4. 若 Type(x) 为 Number 且 Type(y) 为 String,返回 x == ToNumber(y) 的结果。
5. 若 Type(x) 为 String 且 Type(y) 为 Number,返回 ToNumber(x) == y 的结果。
6. 若 Type(x) 为 Boolean,返回 ToNumber(x) == y 的结果。
7. 若 Type(y) 为 Boolean,返回 x == ToNumber(y) 的结果。
8. 若 Type(x) 为 Number 或 String 且 Type(y) 为 Object,返回 x == toPrimitive(y) 的结果。
9. 若 Type(x) 为 Object 且 Type(y) 为 Number 或 String,返回 toPrimitive(x) == y 的结果。
10. 其他,返回 false。
这里解析一道题 [] == ![] // -> true,下面是表达式为何是 true 的步骤:
// [] 转成 true,然后取反变成 fasle
[] == false
// 根据第 7 条得出
[] == ToNumber(false)
[] == 0
// 根据第 9 条得出
toPrimitive([]) == 0
// [].toString() -> ''
'' == 0
// 根据第 5 条得出
0 == 0 // -> true
# 比较运算符
- 如果是对象,通过
toPrimitive转换对象。 - 如果是字符串,通过
unicode字符索引来比较。
# 原型
每个函数都有 prototype 属性,除了 Function.prototype.bind(),该属性指向原型。
每个对象都有 __proto__ 属性,指向创建该对象的构造函数的原型。其实这属性指向了 [[prototype]],但是 [[prototype]] 是内部属性,我们并不能访问,所以使用 __proto__ 来访问。
对象可通过 __proto__ 来寻找不属于该对象的属性,__proto__ 将对象连接起来组成了原型链。
如果想进一步地了解原型,可以仔细阅读 yck 文章 深度解析原型中的各个难点 (opens new window)。同时,以下流程图以 小猪佩奇 为例进行分析:

# new
- 新生成一个空对象
- 链接到原型
- 绑定 this
- 返回新对象
在调用 new 的过程中,会发生以上四件事情,我们也可以试着来自己实现一个 new
function _new() {
// 创建一个空对象
const context = new Object()
// 获得构造函数
const constructor = [].shift.call(arguments)
// 链接到原型
context.__proto__ = constructor.prototype
// 绑定 this,执行构造函数
const result = constructor.apply(context, arguments)
// 确保 new 出来是一个对象
return typeof result === 'object' ? result : context
}
对于实例对象来说,都是通过 new 产生的,无论是 function Foo() 还是 let a = { b: 1 }。
对于创建一个对象来说,更推荐使用字面量的方式创建对象(无论是性能上还是可读性)。因为使用 new Object() 的方式创建对象,需要通过作用链一层层找到 Object,但是使用字面量的方式则没有这个问题。
// function 就是个语法糖
// 内部等同于 new Function()
function Foo() {}
// 这个字面量内部也是使用了 new Object()
let a = { b: 1 }
对于 new 来说,还需要注意运算符优先级。
function Foo() {
return this
}
Foo.getName = function () {
console.log('1')
}
Foo.prototype.getName = function () {
console.log('2')
}
new Foo.getName() // -> 1
new Foo().getName() // -> 2

从上图可以看出,new Foo() 的优先级大于 new Foo。所以对于上述代码来说,可以这样划分执行顺序
new (Foo.getName())
(new Foo()).getName()
对于第一个函数来说,先执行 Foo.getName(),所以结果为 1;对于后者来说,先执行 new Foo() 产生一个实例,然后通过原型链找到 Foo 上的 getName 函数,所以结果为 2。
# instanceof
instanceof 运算符返回一个布尔值,表示对象是否为某个构造函数的实例。
运算符左边是实例对象,右边是构造函数。它会检查右边构造函数的原型对象(prototype)是否在左边对象的原型链上。我们可以试着实现 instanceof
function _instanceof(object, constructor) {
// 获取构造函数的原型(显式)
const prototype = constructor.prototype
// 获取实例对象的原型(隐式)
let __proto__ = object.__proto__
// 判断对象的隐式原型是否等于构造函数的显式原型
while(true) {
if (__proto__ === null) {
return false
}
if (__proto__ === prototype) {
return true
}
__proto__ = __proto__.__proto__
}
}
# this
this 是很多人混淆的概念,但是其实一点也不难,只需要记住以下几个规则则可。
- 全局环境中的
this,指向顶层对象window - 构造函数中的
this,指向实例对象 - 对象方法中的
this,指向方法运行时所在的对象
var a = 1 // 注意:let a = 1,就不一样了喔
function foo() {
console.log(this.a)
}
var obj = {
a: 2,
foo: foo
}
foo() // -> 1
obj.foo() // -> 2
// 以上两者情况 `this`,指向函数调用时所在的对象,优先级是第二个情况大于第一个情况
// 以下情况是优先级最高的,`this` 只会绑定在 `c` 上,不会被任何方式修改 `this` 指向
let c = new foo()
c.a = 3
console.log(c.a) // -> 3
// 还有就是利用 call, apply, bind 改变 this,这个优先级仅次于 new
以上几种情况明白了,很多代码中的 this 应该就没什么问题了,下面让我们看看箭头函数中的 this
function a() {
return () => {
return () => {
console.log(this)
}
}
}
a()()() // -> window
箭头函数其实是没有 this 的,这个函数中 this 只取决于它外面的第一个不是箭头函数的函数的 this。在这个例子中,因为调用 a 符合前面代码中第一种情况,所以 this 是 window。并且,this 一旦绑定了上下文,就不会被任何代码改变。
# 闭包
闭包的概念:指有权访问另外一个函数作用域中的变量的函数。
function A() {
let a = 1
function B() {
console.log(a)
}
return B
}
你是否疑惑,为什么函数 A 已经弹出调用栈了,为什么函数 B 还能引用到函数 A 中的变量。因为函数 A 中的变量这时候已经存储在堆上的。现在 JS 引擎可以通过逃逸分析辨别出哪些变量需要存储在堆上,哪些需要存储在栈上。
经典面试题,循环中使用闭包解决 var 定义函数的问题
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
首先因为 setTimeout 是异步函数,所以会先把循环全部执行完毕,这时候 i 就是 6 了,所以会输出一堆 6,解决办法有三种。
第一种,使用闭包:
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j)
}, j * 1000)
})(i)
}
// ====== 等同于 ======
for (var i = 1; i <= 5; i++) {
function print(i) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
print(i)
}
第二种,使用 setTimeout 第三个参数:
for (var i = 1; i <= 5; i++) {
setTimeout(function timer(j) {
console.log(j)
}, i * 1000, i)
}
第三种,使用 let 定义 i:
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}
因为对于使用 let 来说,他会创建一个块级作用域,相当于
{
// 形成块级作用域
let i = 0
{
let ii = i
setTimeout(function timer() {
console.log(ii)
}, i * 1000)
}
i++
{
let ii = i
}
i++
{
let ii = i
}
...
}
常见应用场景:
- 封装对象私有属性和方法
- 单例模式的实现
- 防抖与节流的实现
# 执行上下文
当执行 JS 代码时,会产生三种执行上下文
- 全局执行上下文
- 函数执行上下文
- eval 执行上下文
每个执行上下文中都有三个重要的属性
- 变量对象(VO),包含变量、函数声明和函数形参,该属性只能在全局上下文中访问
- 作用域链(JS 采用词法作用域,也就是说变量的作用域是在定义时就决定了)
- this
let a = 10
function foo(i) {
let b = 20
}
foo()
对于上述代码,执行栈中有两个上下文:全局上下文和函数 foo 上下文
stack = [
globalContext,
fooContext
]
对于全局上下文来说,VO 大概是这样的
globalContext.VO === global
glovalContext.VO = {
a: undefined,
foo: <Function>
}
对于函数 foo 来说,VO 不能访问,只能访问到活动对象(AO)
fooContext.VO === foo.AO
fooContext.AO {
i: undefined,
b: undefined,
arguments: <>
}
// arguments 是函数独有的对象(箭头函数没有)
// 该对象是一个伪数组,有 `length` 属性且可以通过下标访问元素
// 该对象中的 `callee` 属性代表函数本身
// `caller` 属性代表函数的调用者
对于作用域链,可以把它理解成包含自身变量对象和上级变量对象的列表,通过 [[Scope]] 属性查找上级变量
fooContext.[[Scope]] = [
globalContext.VO
]
fooContext.Scope = fooContext.[[Scope]] + fooContext.VO
fooContext.Scope = [
fooContext.VO,
globalContext.VO
]
接下来让我们看一个老生常谈的例子:var
b() // call b
console.log(a) // undefined
var a = 'Hello World'
function b() {
console.log('call b')
}
想必以上的输出大家肯定都已经明白了,这是因为函数和变量的原因。通常提升的解释是将声明的代码移动到了顶部,这其实没有什么错误,便于大家的理解。但是更准确的解释应该是:在生成执行上下文时,会有两个阶段。第一个阶段是创建的阶段(具体步骤是创建 VO),JS 解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间。对于函数,会将整个函数存入内存中,变量值声明并且赋值为 undefined。所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用。
在提升过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升。
b() // call b second
function b() {
console.log('call b first')
}
function b() {
console.log('call b second')
}
var b = 'Hello World'
var 会产生很多错误,所以在 ES6 中引入了 let。let 不能再声明前使用,但是并不是常说的 let 不会提升,而是 let 提升了声明但没有赋值,因为临时死区导致了并不能在声明前使用。
对于非匿名的立即执行函数需要注意以下一点:
var foo = 1
(function foo() {
foo = 10
console.log(foo)
}()) // -> f foo() { foo = 10 console.log(foo) }
因为当 JS 解释器在遇到非匿名的立即执行函数时,会创建一个辅助的特定对象。然后将函数名称作为这个对象的属性,因此函数内部才可以访问到 foo。但是这个值又是只读的,所以对它的赋值并不生效,所以打印的结果还是这个函数,并且外部的值也没有发生更改。
specialObject = {}
Scope = sepcialObject + Scope
foo = new FunctionExpression
foo.[[scope]] = Scope
specialObject.foo = foo // {DontDelete}, {ReadOnly}
delete Scope[0] // remove specialObject from the front of scope chain
# 深浅拷贝
let a = {
age: 1
}
let b = a
a.age = 2
console.log(b.age) // -> 2
从上述例子中我们可以发现,如果给一个变量赋值一个对象,那么两者的值会是同一个引用。其中一方改变,另一方也会相应地改变。
但是开发中,我们不希望出现这样的问题,则可以使用浅拷贝来解决这个问题。
# 浅拷贝
首先可以通过 Object.assign 来解决这个问题。
let a = {
age: 1
}
let b = Object.assign({}, a)
a.age = 2
console.log(b.age) // -> 1
当然,我们也可以通过扩展运算符(...)来解决
let a = {
age: 1
}
let b = {...a}
a.age = 2
console.log(b) // -> 1
通常浅拷贝就可以解决大部分问题,但当我们遇到以下问题,就需要使用深拷贝
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = {...a}
a.jobs.first = 'EF'
console.log(b.jobs.first) // -> EF
浅拷贝只解决了第一层的问题,如果接下去的值还有对象的话,那么就又回到刚开始的话题,两者享有相同的引用。要解决这个问题,我们需要引入深拷贝。
# 深拷贝
这个问题通常可以通过 JSON.parse(JSON.stringify(object)) 来解决。
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = JSON.parse(JSON.stringify(a))
a.jobs.first = 'EF'
console.log(b.jobs.first) // -> FE
但是该方法也是有局限性的:
- 会忽略
undefined - 会忽略
symbol - 不能序列化函数
- 不能解决循环引用对象
let obj = {
a: 1,
b: {
c: 2,
d: 3
}
}
obj.c = obj.b
obj.e = obj.a
obj.b.c = obj.b
obj.b.e = obj.b.c
let newObj = JSON.parse(JSON.stringify(obj))
console.log(newObje)
如果你有这么一个循环引用对象,你会发现你不能通过该方法深拷贝

在遇到 undefined、symbol、函数的时候,该对象也不能正常序列化
let a = {
age: undefined,
sex: Symbol('male'),
jobs: function () {},
name: 'qiuzi'
}
let b = JSON.parse(JSON.stringify())
console.log(b) // { name: 'qiuzi' }
你会发现在上述情况中,该方法会省略 undefined 和函数。
但是在通常情况下,复杂数据都是序列化的,所以这个函数可以解决大部分问题,并且该函数是内置函数,处理深拷贝性能最快。当然,如果你的数据中含有以上三种情况,可以使用 lodash 的深拷贝函数 (opens new window) 或自行封装 cloneDeep 方法,参考文章 如何写出一个惊艳面试官的深拷贝 (opens new window)。
如果你所需拷贝的独享含有内置类型并且不包含函数,可以使用 MessageChannel
function structuralClone(obj) {
return new Promise(resolve => {
const { port1, port2 } = new MessageChannel()
port2.onmessage = ev => resolve(ev.data)
port1.postMessage(obj)
})
}
let obj = {
a: 1,
b: {
c: b
}
}
// 注意:该方法是异步的,可以处理 undefined 和循环引用对象
(async () => {
const clone = await structuralClone(obj)
})
# 模块化
JS 模块目前主流有 ES6 模块与 CommonJS 模块。除此之外,还有逐渐被淘汰的 AMD(Require.js) 与 CMD(Sea.js)。其中,ES6 模块与 CommonJS 模块主要有三个差异:
- CommonJS 模块输出的是一个值得拷贝,ES6 模块输出的是值得引用
- CommonJS 模块是运行时加载,ES6 模块是编译时输出接口
- CommonJS 模块的
require()是同步加载模块,ES6 模块的import命令是异步加载,有一个独立的模块依赖的解析阶段
# CommonJS
CommonJS 是 Node 独有的规范
// a.js
module.exports = { a: 1 }
// or
exports.a = 1
// b.js
let module = require('./a.js')
module.a // -> 1
在上述代码中,module.exports 和 exports 很容易混淆,让我们看看大致内部实现
let module = require('./a.js')
module.a
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了,
// 重要的是 module 这里, module 是 Node 独有的一个变量
module.exports = { a: 1 }
// 基本实现
let module = {
exports: {} // exports 就是个空对象
}
// 这个是为什么 exports 和 module.exports 用法相似的原因
let exports = module.exports
let load = function (module) {
// 导出的东西
let a = 1
module.exports = a
return module.exports
}
再来说说 module.exports 和 exports,用法其实是相似的,但是不能对 exports 直接赋值,不会有任何效果。
# ES6 模块
ES6 模块是在 JavaScript 语言标准的层面上实现的模块功能
// a.js
export let a = 1
// b.js
import { a } from './a.js'
console.log(a) // -> 1
# 防抖
你是否在日常开发中遇到一个问题,在滚动事件中需要做复杂计算或者实现一个按钮的防二次点击操作。
这些需求都可以通过函数防抖来实现。尤其第一个需求,如果在频繁的事件回调中做复杂计算,很有可能导致页面卡顿,不如将多次计算合并为一次计算,只在一个准确点做操作。
PS:防抖和节流的作用都是防止函数多次调用。区别在于,若一个用户一直触发这个函数,且每次触发函数的间隔小于 wait,防抖的情况下只会调用一次;而节流的情况下,会每隔一定时间(参数 wait)调用函数。
我们先来看一个袖珍版的防抖,理解一下防抖的实现:
/**
* @param {Function} func - 回调函数
* @param {number} wait - 等待时间
* @return {Function}
*/
function debounce(func, wait = 50) {
let timer = null
return function(...args) {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
这是一个简单版的防抖,但是有缺陷,这个防抖只能在最后调用。一般的防抖会有 immediate 选项,表示是否立即调用。这两者的区别,举个栗子来说:
- 例如在搜索引擎搜索问题的时候,我们希望用户输入完最后一个字才调用查询接口。这个时候,使用
延迟执行的防抖函数,它总是一连串(间隔小于 wait)函数触发之后调用。 - 例如用户给
yck的 interviewMap 点 star 时,我们希望用户点第一下时候去调用接口,并且成功之后改变 star 按钮的样子,用户就可以立马得到反馈是否 star 成功。这个情况使用立即执行的防抖函数,它总是在第一次调用,并且下一次调用必须与前一次调用的时间间隔大于 wait 才会触发。
下面我们来实现一个带有立即执行选项的防抖函数
// 这个是用来获取当前时间戳的
function now() {
return + new Date()
}
/**
* 防抖函数,返回函数连续调用时,空闲时间必须大于或等于 wait,func 才会执行
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗口的间隔
* @param {boolean} immediate 设置为 true 时,是否立即调用函数
* @param {function}
*/
function debounce (fun, wait = 50, immediate = true) {
let timer, context, args
// 延迟执行函数
const later = () => {
setTimeout(() => {
// 延迟函数执行完毕,清空缓存的定时器序号
timer = null
// 延迟执行的情况下,函数会在延迟函数中执行
// 使用到之前缓存的参数和上下文
if (!immediate) {
func.apply(context, args)
context = args = null
}
}, wait)
// 这里返回的函数是每次实际调用的函数
return function(...params) {
// 如果没有创建延迟执行函数(later),就创建一个
if (!timer) {
timer = later()
// 如果是立即执行函数,调用函数
// 否则缓存函数和调用上下文
if (immediate) {
func.apply(this, params)
} else {
context = this
args = params
}
// 如果已有延迟执行函数(later),调用的时候清除原来的并重新设计一个
// 这样做延迟函数会重新计时
} else {
clearTimeout(timer)
timer = later()
}
}
}
}
整体函数实现并不难,总结一下。
- 对于按钮防点击实现:如果函数是立即执行的,就立即调用。如果函数是延迟执行,就缓存上下文和参数,放到延迟函数中执行。一旦开始一个定时器,只有定时器还在,每次点击都会重新计时。一旦点累了,定时器时间到了,定时器重置为
null,就可以再次点击了。 - 对于延迟执行函数实现:清除定时器 ID,如果是延迟调用,就调用函数。
# 节流
防抖和节流的本质是不一样的。防抖是将多次执行变为最后一次执行,节流是将多次执行变成每隔一段时间执行。
/**
* underscore 节流函数,返回函数连续调用时,func 执行频率限定为 次 / wait
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗口的间隔
* @param {object} options 如果想忽略开始函数的调用,传入 { leading: false }
* 如果想忽略结尾函数的调用,传入 { trailing: false }
* 两者不能共存,否则函数不能执行
*
* @return {function} 返回客户调用函数
*/
_.throttle = (func, wait, options) => {
let context, args, result
let timeout = null
// 之前的时间戳
let previous = 0
// 如果 options 没传,则设为空对象
if (!options) {
options = {}
}
// 定时器回调函数
let later = () => {
// 如果设置了 leading,就将 previous 设为 0
// 用于下面函数的第一个 if 判断
previous = options.leading === false ? 0 : _.now()
// 置空,一是为了防止内存泄漏;二是为了下面的定时器判断
timeout = null
result = func.apply(context, args)
if (!timeout) {
args = null
context = null
}
}
return function() {
let now = _.now()
}
}
# 为什么 0.1 + 0.2 != 0.3
因为 JS 采用 IEEE 754 双精度版本(64位),并且只要采用 IEEE 754 的语言都有该问题。
计算机表示十进制是采用二进制表示的,所以 0.1 在二进制表示为
// (0011) 表示循环
0.1 = 2^-4 * 1.10011(0011)
那么如何得到这个二进制呢,我们可以演算一下
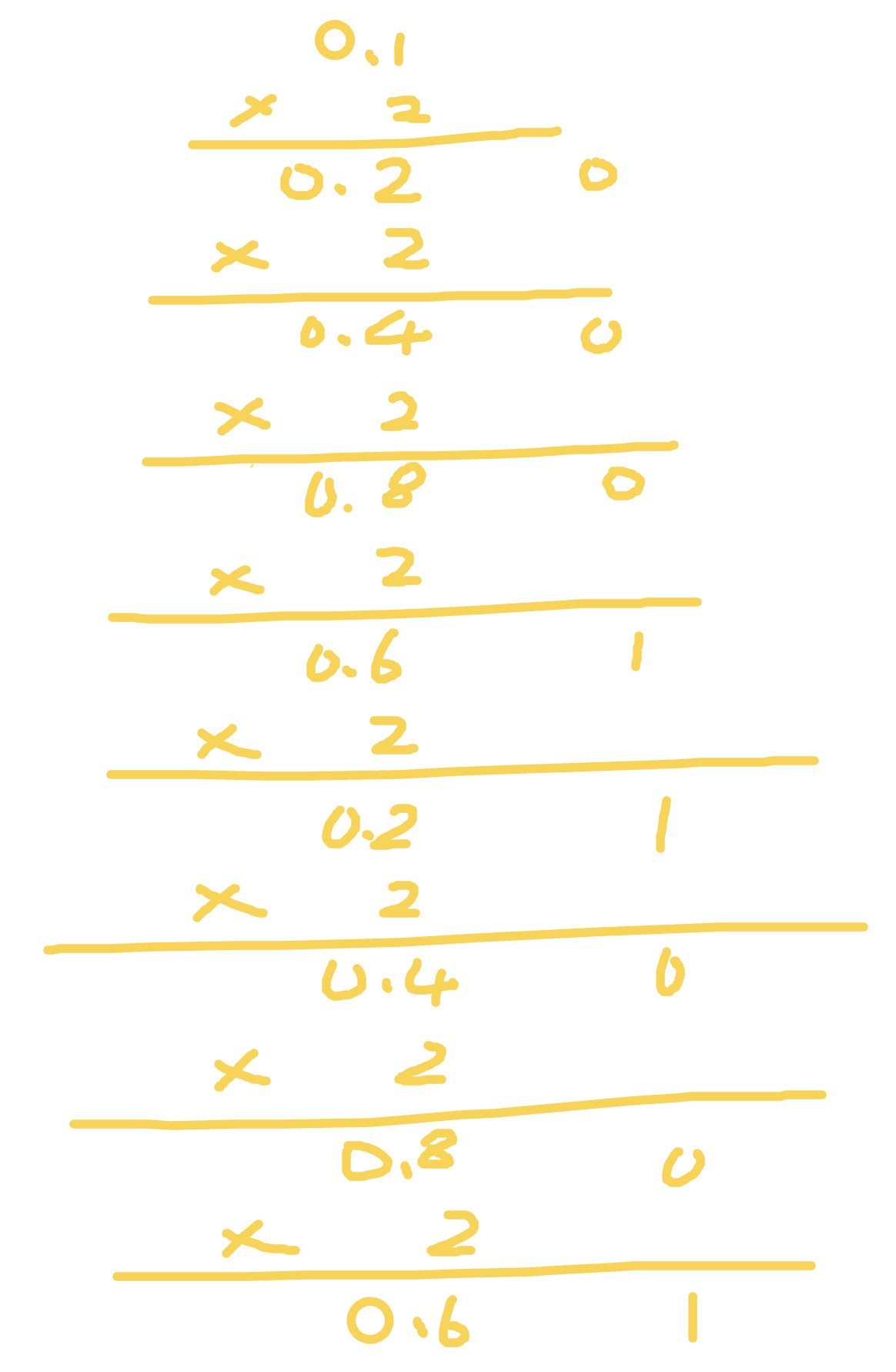 //
//
小数算二进制和整数不同。乘法计算时,只计算小数位,整数位用作每一位的二进制,并且得到的第一位是最高位。因此可以得出 0.1 = 2^-4 * 1.10011(0011),那么 0.2 的演算也基本如上所示,只需要去掉第一步乘法,所以得出 0.2 = 2^-3 * 1.10011(0011)。
回来继续说 IEEE 754 双精度。六十四位中符号位占一位,整数位占十一位,其余五十二位都为小数位。因为 0.1 和 0.2 都是无限循环的二进制,所以在小数位末尾处需要判断是否进位(就和十进制的四舍五入一样)。
所以 2^-4 * 1.10011...001 进位后就变成了 2^-4 * 1.10011(0011 * 12次)010 。那么把这两个二进制加起来会得出 2^-2 * 1.0011(0011 * 11次)0100 , 这个值算成十进制就是 0.30000000000000004。
下面说一下原生解决办法,如下代码所示
parseFloat((0.1 + 0.2).toFixed(10))